Technology Stack
Server-side
Client-side
Hosting
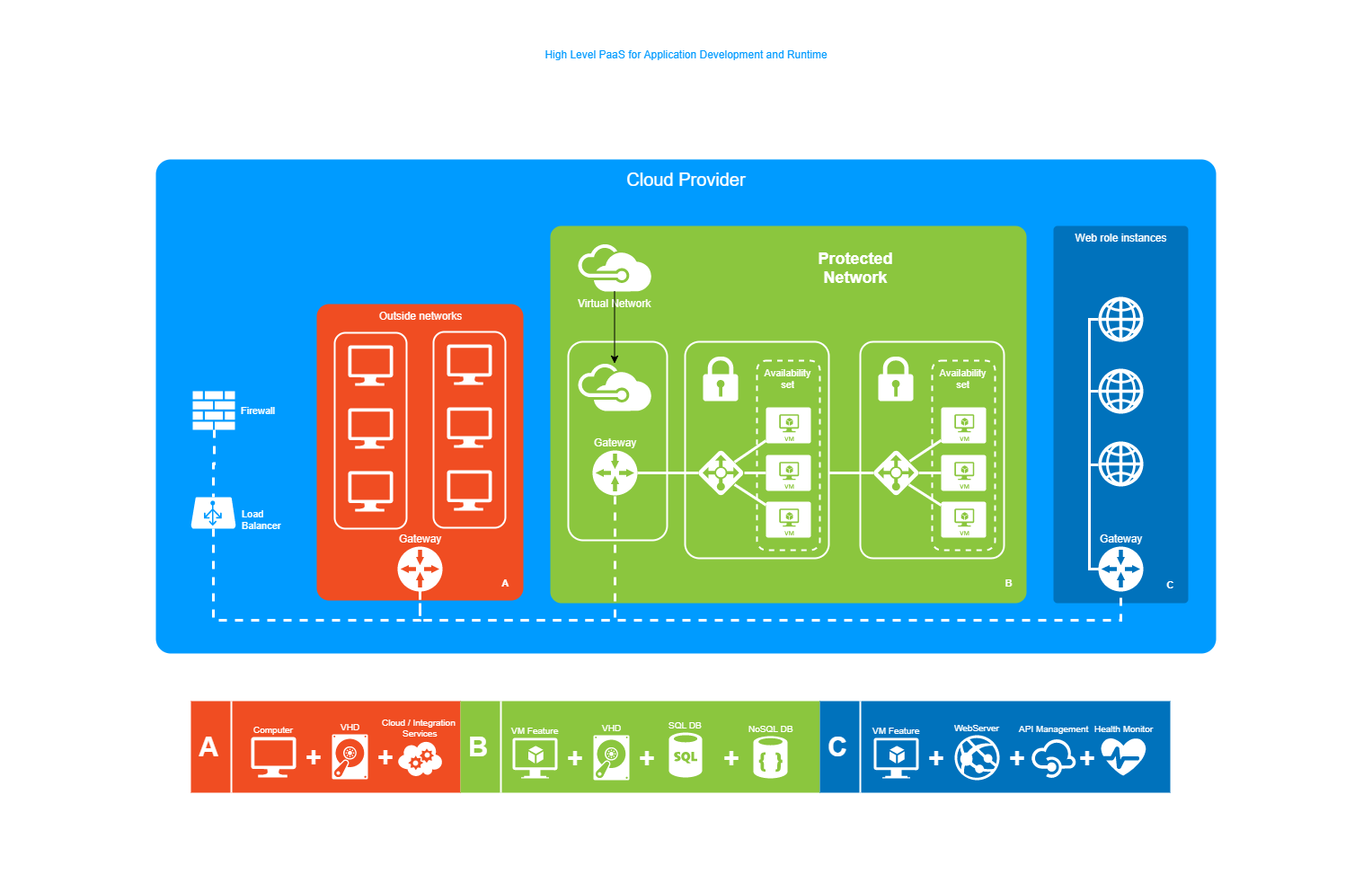
Solution Architecture
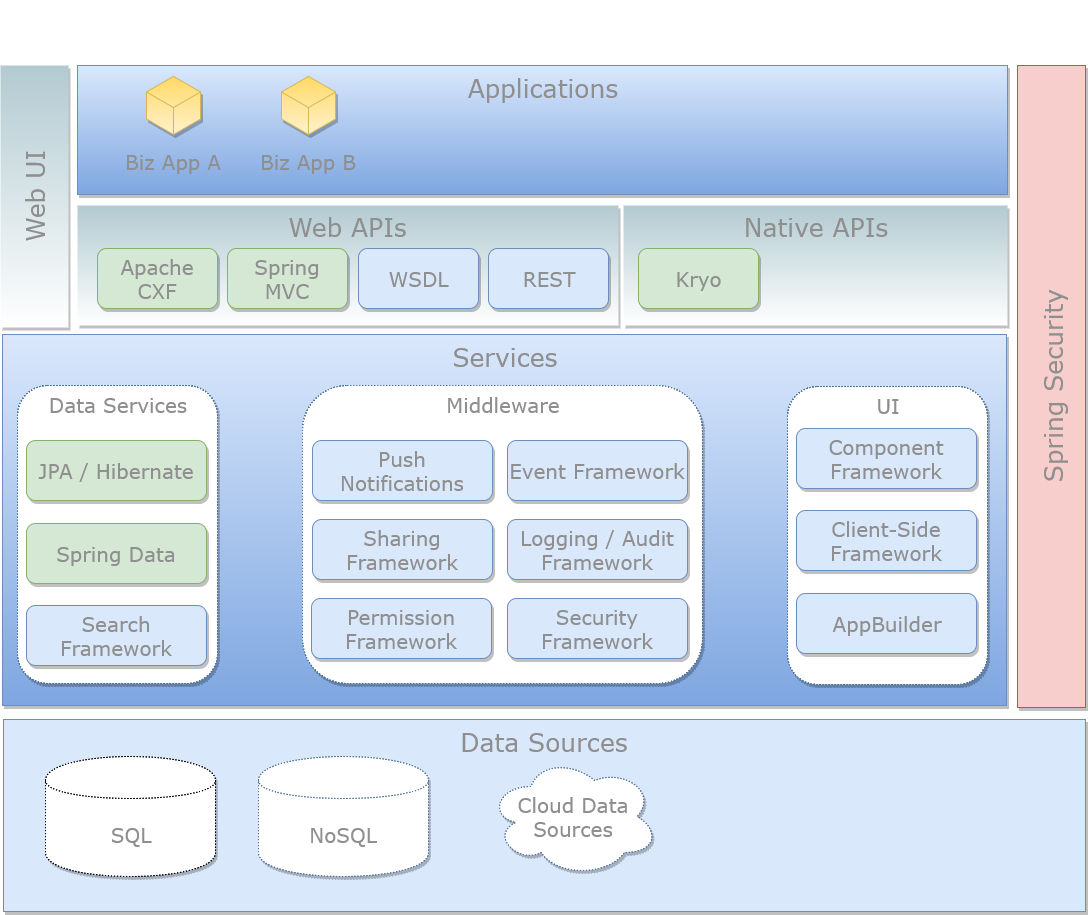
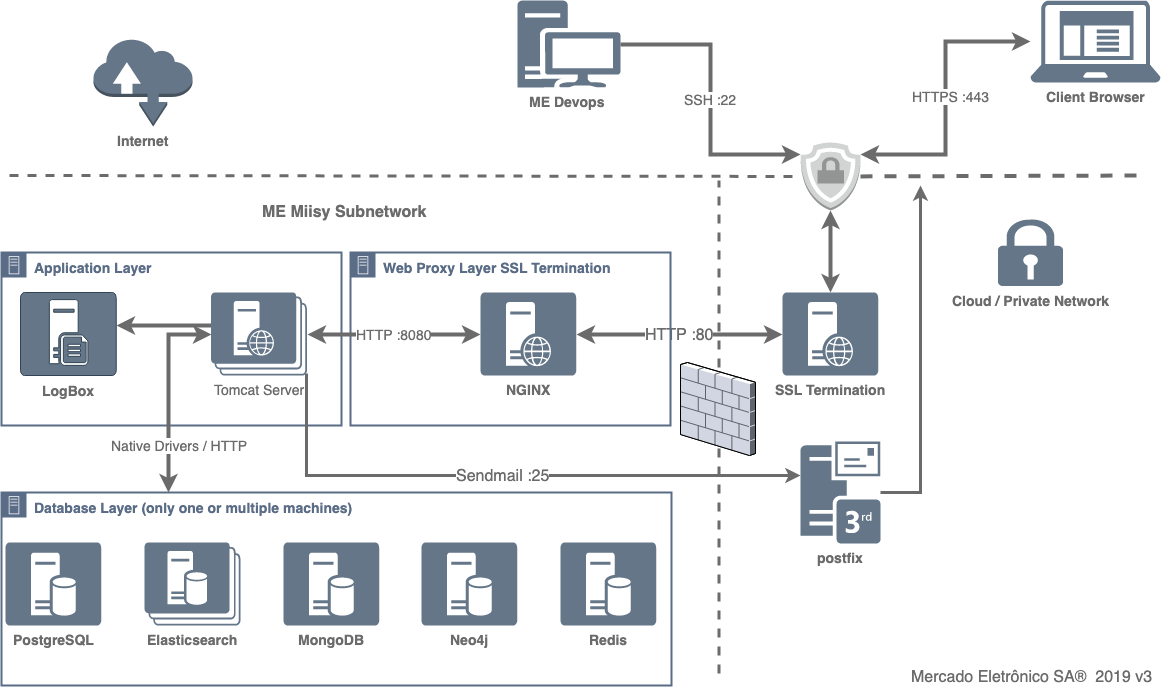
Servers Architecture
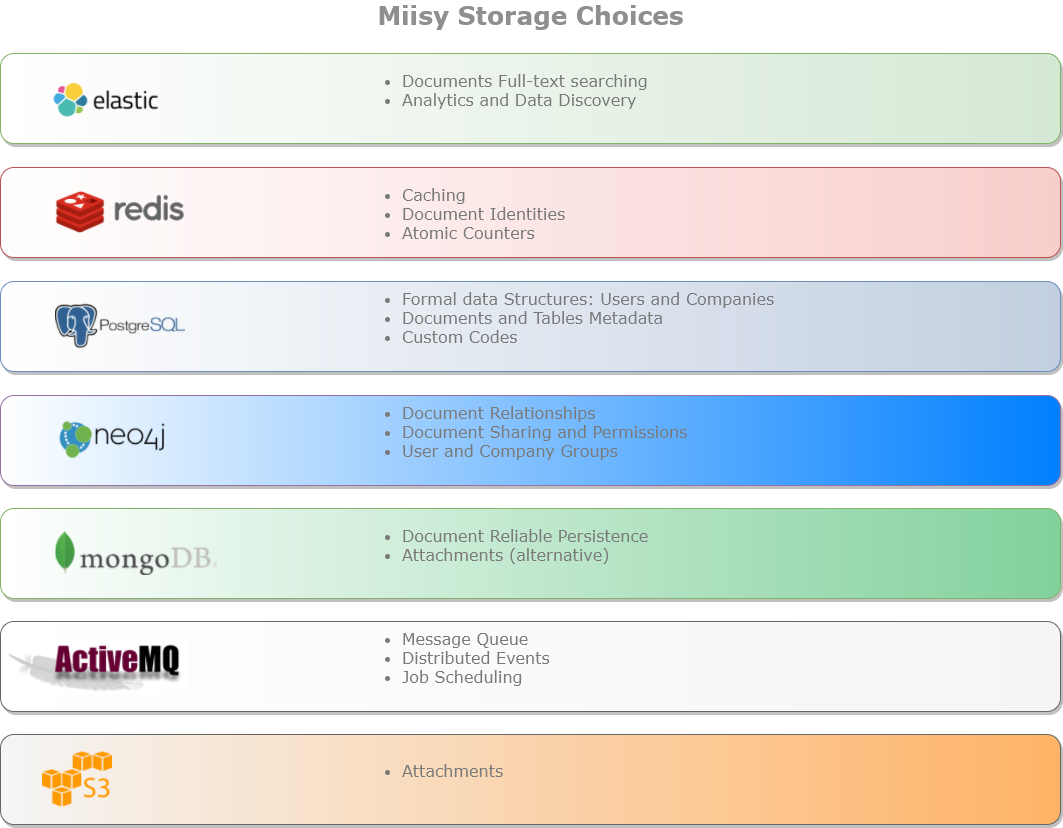
Storage
Java 11
source: https://docs.oracle.com/javase/specs/jls/se11/html/index.html
The Java® programming language is a general-purpose, concurrent, class-based, object-oriented language. It is designed to be simple enough that many programmers can achieve fluency in the language. The Java programming language is related to C and C++ but is organized rather differently, with a number of aspects of C and C++ omitted and a few ideas from other languages included. It is intended to be a production language, not a research language, and so, as C. A. R. Hoare suggested in his classic paper on language design, the design has avoided including new and untested features.
The Java programming language is strongly and statically typed. This specification clearly distinguishes between the compile-time errors that can and must be detected at compile time, and those that occur at run time. Compile time normally consists of translating programs into a machine-independent byte code representation. Run-time activities include loading and linking of the classes needed to execute a program, optional machine code generation and dynamic optimization of the program, and actual program execution.
The Java programming language is a relatively high-level language, in that details of the machine representation are not available through the language. It includes automatic storage management, typically using a garbage collector, to avoid the safety problems of explicit deallocation (as in C's free or C++'s delete). High-performance garbage-collected implementations can have bounded pauses to support systems programming and real-time applications. The language does not include any unsafe constructs, such as array accesses without index checking, since such unsafe constructs would cause a program to behave in an unspecified way.
The Java programming language is normally compiled to the bytecode instruction set and binary format defined in The Java Virtual Machine Specification, Java SE 11 Edition.
SpringBoot
source: https://projects.spring.io/spring-boot/
Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can "just run". We take an opinionated view of the Spring platform and third-party libraries so you can get started with minimum fuss. Most Spring Boot applications need very little Spring configuration.
Features * Create stand-alone Spring applications * Embed Tomcat, Jetty or Undertow directly (no need to deploy WAR files) * Provide opinionated 'starter' POMs to simplify your Maven configuration * Automatically configure Spring whenever possible * Provide production-ready features such as metrics, health checks and externalized configuration * Absolutely no code generation and no requirement for XML configuration
Spring MVC
source: http://www.tutorialspoint.com/spring/spring_web_mvc_framework.htm
The Spring web MVC framework provides model-view-controller architecture and ready components that can be used to develop flexible and loosely coupled web applications. The MVC pattern results in separating the different aspects of the application (input logic, business logic, and UI logic), while providing a loose coupling between these elements.
-
The Model encapsulates the application data and in general they will consist of POJO.
-
The View is responsible for rendering the model data and in general it generates HTML output that the client's browser can interpret.
-
The Controller is responsible for processing user requests and building appropriate model and passes it to the view for rendering.
The DispatcherServlet
The Spring Web model-view-controller (MVC) framework is designed around a DispatcherServlet that handles all the HTTP requests and responses. The request processing workflow of the Spring Web MVC DispatcherServlet is illustrated in the following diagram:
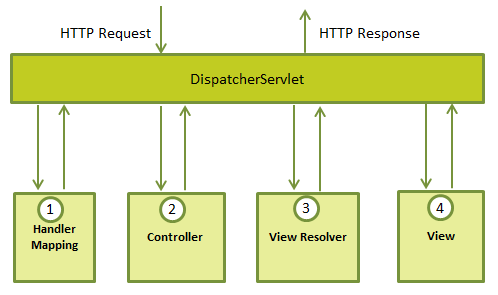
Following is the sequence of events corresponding to an incoming HTTP request to DispatcherServlet:
-
After receiving an HTTP request, DispatcherServlet consults the HandlerMapping to call the appropriate Controller.
-
The Controller takes the request and calls the appropriate service methods based on used GET or POST method. The service method will set model data based on defined business logic and returns view name to the DispatcherServlet.
-
The DispatcherServlet will take help from ViewResolver to pickup the defined view for the request.
-
Once view is finalized, The DispatcherServlet passes the model data to the view which is finally rendered on the browser.
All the above mentioned components ie. HandlerMapping, Controller and ViewResolver are parts of WebApplicationContext which is an extension of the plain ApplicationContext with some extra features necessary for web applications.
Apache CXF
source: https://cxf.apache.org/
Overview
Apache CXF is an open source services framework. CXF helps you build and develop services using frontend programming APIs, like JAX-WS and JAX-RS. These services can speak a variety of protocols such as SOAP, XML/HTTP, RESTful HTTP, or CORBA and work over a variety of transports such as HTTP, JMS or JBI.
Features
CXF includes a broad feature set, but it is primarily focused on the following areas:
- Web Services Standards Support: CXF supports a variety of web service standards including SOAP, the WS-I Basic Profile, WSDL, WS-Addressing, WS-Policy, WS-ReliableMessaging, WS-Security, WS-SecurityPolicy, WS-SecureConverstation, and WS-Trust (partial).
- Frontends: CXF supports a variety of "frontend" programming models.
CXF implements the JAX-WS APIs. CXF JAX-WS support includes some extensions to the standard that make it significantly easier to use, compared to the reference implementation: It will automatically generate code for request and response bean classes, and does not require a WSDL for simple cases.
It also includes a "simple frontend" which allows creation of clients and endpoints without annotations. CXF supports both contract first development with WSDL and code first development starting from Java.
For REST, CXF also supports a JAX-RS frontend.
- Ease of use: CXF is designed to be intuitive and easy to use. There are simple APIs to quickly build code-first services, Maven plug-ins to make tooling integration easy, JAX-WS API support, Spring 2.x XML support to make configuration a snap, and much more.
- Binary and Legacy Protocol Support: CXF has been designed to provide a pluggable architecture that supports not only XML but also non-XML type bindings, such as JSON and CORBA, in combination with any type of transport.
Groovy
source: http://www.groovy-lang.org/
Apache Groovy is a powerful, optionally typed and dynamic language, with static-typing and static compilation capabilities, for the Java platform aimed at improving developer productivity thanks to a concise, familiar and easy to learn syntax. It integrates smoothly with any Java program, and immediately delivers to your application powerful features, including scripting capabilities, Domain-Specific Language authoring, runtime and compile-time meta-programming and functional programming.
Flat learning curve
Concise, readable and expressive syntax, easy to learn for Java developers
Smooth Java integration
Seamlessly and transparently integrates and interoperates with Java and any third-party libraries
Vibrant and rich ecosystem
Web development, reactive applications, concurrency / asynchronous / parallelism library, test frameworks, build tools, code analysis, GUI building
Powerful features
Closures, builders, runtime & compile-time meta-programming, functional programming, type inference, and static compilation
Domain-Specific Languages
Flexible & malleable syntax, advanced integration & customization mechanisms, to integrate readable business rules in your applications
Scripting and testing glue
Great for writing concise and maintainable tests, and for all your build and automation tasks
Javascript
source: http://www.howtocreate.co.uk/tutorials/javascript/introduction
JavaScript is a programming language that can be included on web pages to make them more interactive. You can use it to check or modify the contents of forms, change images, open new windows and write dynamic page content. You can even use it with CSS to make DHTML (Dynamic HyperText Markup Language). This allows you to make parts of your web pages appear or disappear or move around on the page. JavaScripts only execute on the page(s) that are on your browser window at any set time. When the user stops viewing that page, any scripts that were running on it are immediately stopped. The only exceptions are cookies or various client side storage APIs, which can be used by many pages to store and pass information between them, even after the pages have been closed.
Before we go any further, let me say; JavaScript has nothing to do with Java. If we are honest, JavaScript, originally nicknamed LiveWire and then LiveScript when it was created by Netscape, should in fact be called ECMAscript as it was renamed when Netscape passed it to the ECMA for standardisation.
JavaScript is a client side, interpreted, object oriented, high level scripting language, while Java is a client side, compiled, object oriented high level language. Now after that mouthful, here's what it means.
Client side
Programs are passed to the computer that the browser is on, and that computer runs them. The alternative is server side, where the program is run on the server and only the results are passed to the computer that the browser is on. Examples of this would be PHP, Perl, ASP, JSP etc.
Interpreted
The program is passed as source code with all the programming language visible. It is then converted into machine code as it is being used. Compiled languages are converted into machine code first then passed around, so you never get to see the original programming language. Java is actually dual half compiled, meaning it is half compiled (to 'byte code') before it is passed, then executed in a virtual machine which converts it to fully compiled code just before use, in order to execute it on the computer's processor. Interpreted languages are generally less fussy about syntax and if you have made mistakes in a part they never use, the mistake usually will not cause you any problems.
Scripting
This is a little harder to define. Scripting languages are often used for performing repetitive tasks. Although they may be complete programming languages, they do not usually go into the depths of complex programs, such as thread and memory management. They may use another program to do the work and simply tell it what to do. They often do not create their own user interfaces, and instead will rely on the other programs to create an interface for them. This is quite accurate for JavaScript. We do not have to tell the browser exactly what to put on the screen for every pixel (though there is a relatively new API known as canvas that makes this possible if needed), we just tell it that we want it to change the document, and it does it. The browser will also take care of the memory management and thread management, leaving JavaScript free to get on with the things it wants to do.
High level
Written in words that are as close to english as possible. The contrast would be with assembly code, where each command can be directly translated into machine code.
Coffeescript
source: http://coffeescript.org/
CoffeeScript is a little language that compiles into JavaScript. Underneath that awkward Java-esque patina, JavaScript has always had a gorgeous heart. CoffeeScript is an attempt to expose the good parts of JavaScript in a simple way.
The golden rule of CoffeeScript is: "It's just JavaScript". The code compiles one-to-one into the equivalent JS, and there is no interpretation at runtime. You can use any existing JavaScript library seamlessly from CoffeeScript (and vice-versa). The compiled output is readable and pretty-printed, will work in every JavaScript runtime, and tends to run as fast or faster than the equivalent handwritten JavaScript.
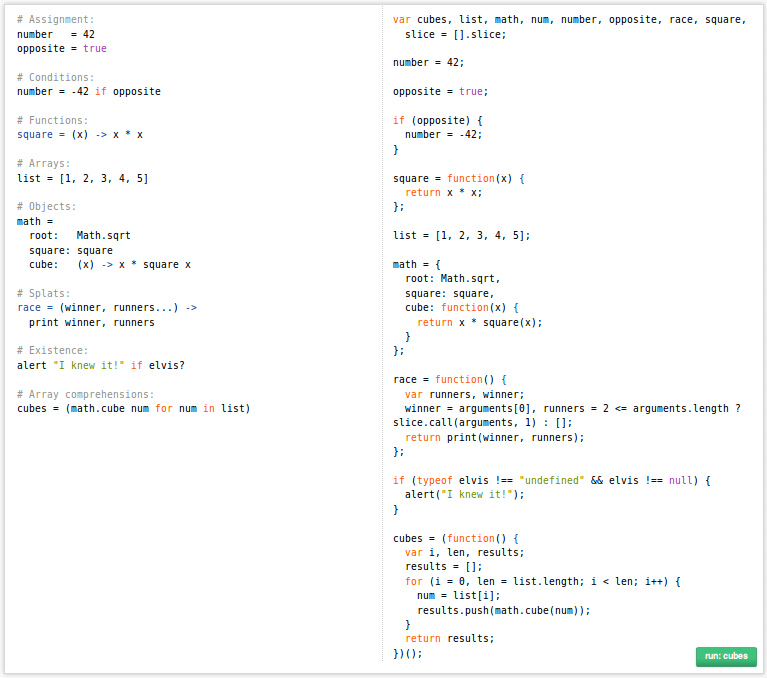
Overview
CoffeeScript on the left, compiled JavaScript output on the right.
CSS
source: http://www.w3schools.com/css/css_intro.asp
- CSS stands for Cascading Style Sheets
- CSS describes how HTML elements are to be displayed on screen, paper, or in other media
- CSS saves a lot of work. It can control the layout of multiple web pages all at once
- External stylesheets are stored in CSS files
- CSS is used to define styles for your web pages, including the design, layout and variations in display for different devices and screen sizes.
CSS Solved a Big Problem
HTML was NEVER intended to contain tags for formatting a web page!
HTML was created to describe the content of a web page.
When tags like < font >, and color attributes were added to the HTML 3.2 specification, it started a nightmare for web developers. Development of large websites, where fonts and color information were added to every single page, became a long and expensive process.
To solve this problem, the World Wide Web Consortium (W3C) created CSS.
CSS removed the style formatting from the HTML page!
CSS Saves a Lot of Work!
The style definitions are normally saved in external .css files.
With an external stylesheet file, you can change the look of an entire website by changing just one file!
Modernizr
source: https://modernizr.com/docs/#what-is-feature-detection
Modernizr is a small piece of JavaScript code that automatically detects the availability of next-generation web technologies in your user's browsers. Rather than blacklisting entire ranges of browsers based on “UA sniffing,” Modernizr uses feature detection to allow you to easily tailor your user's experiences based on the actual capabilities of their browser.
With this knowledge that Modernizr gives you, you can take advantage of these new features in the browsers that can render or utilize them, and still have easy and reliable means of controlling the situation for the browsers that cannot.
In the dark ages of web development, we often had to resort to UA sniffing in order to determine if their user's would be able to make use of Awesome-New-Feature™. In practice, that means doing something like the following
if (browser === "the-one-they-make-you-use-at-work") {
getTheOldLameExperience();
} else {
showOffAwesomeNewFeature();
}
Now that looks ok, right? We are using Awesome-New-Feature™, and of course it isn't supported in an old crusty browser like that, right? That could very well be the case - today. But what if the next version of that browser adds support for Awesome-New-Feature™? Now you have to go back and audit your code, updating every single place that you are doing this check. That is assuming that you have the time to find out about every feature update for every single browser. Worse still, until you realize that it actually works in the newest version, all of those users back at the office getTheOldLameExperience, for no reason whatsoever.
Those users - given a substandard website for apparently no reason - can actually go into their browser and OS settings and change the name of the browser (or user-agent - what we compare against in code when preforming a UA sniff) to whatever they would like. At that point - your code is meaningless. You are blocking out users who may actually support all of your features, and possibly letting those in who don't. Nearly everyone gets a broken experience. There has to be a better way!
There is, and it is called Feature Detection, and it looks more like this
if (Modernizr.awesomeNewFeature) {
showOffAwesomeNewFeature();
} else {
getTheOldLameExperience();
}
Rather than basing your decisions on whether or not the user is on the one-they-make-you-use-at-work browser, and assuming that means they either do or do not have access to Awesome-New-Feature™, feature detection actually programmatically checks if Awesome-New-Feature™ works in the browser, and gives you either a true or false result. So now as soon as your least favorite browser adds support for Awesome-New-Feature™, your code works there - automatically! No more having to update, ever. The code ends up being similar, but much more clear to its actual intention
jQuery 1.11.x
[source: https://jquery.com/ ](https://jquery.com/(https://jquery.com/)
http://api.jquery.com/
jQuery is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and Ajax much simpler with an easy-to-use API that works across a multitude of browsers. With a combination of versatility and extensibility, jQuery has changed the way that millions of people write JavaScript.
jQuery API
jQuery is a fast, small, and feature-rich JavaScript library. It makes things like HTML document traversal and manipulation, event handling, animation, and Ajax much simpler with an easy-to-use API that works across a multitude of browsers.
Postgresql
source: http://www.postgresql.org/about/
PostgreSQL is a powerful, open source object-relational database system. It has more than 15 years of active development and a proven architecture that has earned it a strong reputation for reliability, data integrity, and correctness. It runs on all major operating systems, including Linux, UNIX (AIX, BSD, HP-UX, SGI IRIX, Mac OS X, Solaris, Tru64), and Windows. It is fully ACID compliant, has full support for foreign keys, joins, views, triggers, and stored procedures (in multiple languages). It includes most SQL:2008 data types, including INTEGER, NUMERIC, BOOLEAN, CHAR, VARCHAR, DATE, INTERVAL, and TIMESTAMP. It also supports storage of binary large objects, including pictures, sounds, or video. It has native programming interfaces for C/C++, Java, .Net, Perl, Python, Ruby, Tcl, ODBC, among others, and exceptional documentation.
An enterprise class database, PostgreSQL boasts sophisticated features such as Multi-Version Concurrency Control (MVCC), point in time recovery, tablespaces, asynchronous replication, nested transactions (savepoints), online/hot backups, a sophisticated query planner/optimizer, and write ahead logging for fault tolerance. It supports international character sets, multibyte character encodings, Unicode, and it is locale-aware for sorting, case-sensitivity, and formatting. It is highly scalable both in the sheer quantity of data it can manage and in the number of concurrent users it can accommodate. There are active PostgreSQL systems in production environments that manage in excess of 4 terabytes of data.
Featureful and Standards Compliant
PostgreSQL prides itself in standards compliance. Its SQL implementation strongly conforms to the ANSI-SQL:2008 standard. It has full support for subqueries (including subselects in the FROM clause), read-committed and serializable transaction isolation levels. And while PostgreSQL has a fully relational system catalog which itself supports multiple schemas per database, its catalog is also accessible through the Information Schema as defined in the SQL standard.
Data integrity features include (compound) primary keys, foreign keys with restricting and cascading updates/deletes, check constraints, unique constraints, and not null constraints.
It also has a host of extensions and advanced features. Among the conveniences are auto-increment columns through sequences, and LIMIT/OFFSET allowing the return of partial result sets. PostgreSQL supports compound, unique, partial, and functional indexes which can use any of its B-tree, R-tree, hash, or GiST storage methods.
GiST (Generalized Search Tree) indexing is an advanced system which brings together a wide array of different sorting and searching algorithms including B-tree, B+-tree, R-tree, partial sum trees, ranked B+-trees and many others. It also provides an interface which allows both the creation of custom data types as well as extensible query methods with which to search them. Thus, GiST offers the flexibility to specify what you store, how you store it, and the ability to define new ways to search through it --- ways that far exceed those offered by standard B-tree, R-tree and other generalized search algorithms.
GiST serves as a foundation for many public projects that use PostgreSQL such as OpenFTS and PostGIS. OpenFTS (Open Source Full Text Search engine) provides online indexing of data and relevance ranking for database searching. PostGIS is a project which adds support for geographic objects in PostgreSQL, allowing it to be used as a spatial database for geographic information systems (GIS), much like ESRI's SDE or Oracle's Spatial extension.
Other advanced features include table inheritance, a rules systems, and database events. Table inheritance puts an object oriented slant on table creation, allowing database designers to derive new tables from other tables, treating them as base classes. Even better, PostgreSQL supports both single and multiple inheritance in this manner.
The rules system, also called the query rewrite system, allows the database designer to create rules which identify specific operations for a given table or view, and dynamically transform them into alternate operations when they are processed.
The events system is an interprocess communication system in which messages and events can be transmitted between clients using the LISTEN and NOTIFY commands, allowing both simple peer to peer communication and advanced coordination on database events. Since notifications can be issued from triggers and stored procedures, PostgreSQL clients can monitor database events such as table updates, inserts, or deletes as they happen.
Mongodb
source: http://www.tutorialspoint.com/mongodb/mongodb_overview.htm
MongoDB is a cross-platform, document oriented database that provides, high performance, high availability, and easy scalability. MongoDB works on concept of collection and document.
Database
Database is a physical container for collections. Each database gets its own set of files on the file system. A single MongoDB server typically has multiple databases.
Collection
Collection is a group of MongoDB documents. It is the equivalent of an RDBMS table. A collection exists within a single database. Collections do not enforce a schema. Documents within a collection can have different fields. Typically, all documents in a collection are of similar or related purpose.
Document
A document is a set of key-value pairs. Documents have dynamic schema. Dynamic schema means that documents in the same collection do not need to have the same set of fields or structure, and common fields in a collection's documents may hold different types of data.
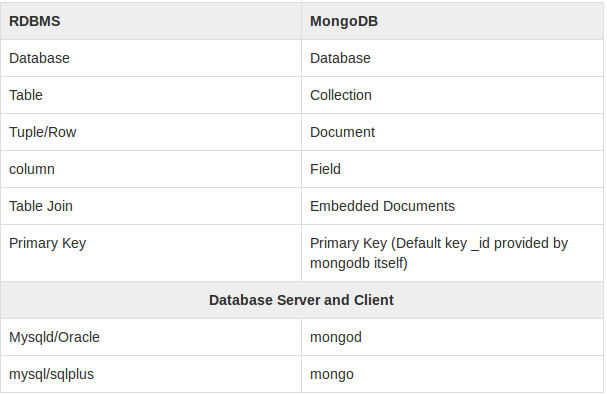
Below given table shows the relationship of RDBMS terminology with MongoDB
Sample document
Below given example shows the document structure of a blog site which is simply a comma separated key value pair.
{
_id: ObjectId(7df78ad8902c)
title: 'MongoDB Overview',
description: 'MongoDB is no sql database',
by: 'tutorials point',
url: 'http://www.tutorialspoint.com',
tags: ['mongodb', 'database', 'NoSQL'],
likes: 100,
comments: [
{
user:'user1',
message: 'My first comment',
dateCreated: new Date(2011,1,20,2,15),
like: 0
},
{
user:'user2',
message: 'My second comments',
dateCreated: new Date(2011,1,25,7,45),
like: 5
}
]
}
_id is a 12 bytes hexadecimal number which assures the uniqueness of every document. You can provide _id while inserting the document. If you didn't provide then MongoDB provide a unique id for every document. These 12 bytes first 4 bytes for the current timestamp, next 3 bytes for machine id, next 2 bytes for process id of mongodb server and remaining 3 bytes are simple incremental value.
Redis
source: http://redis.io/topics/introduction
Redis is an open source (BSD licensed), in-memory data structure store, used as database, cache and message broker. It supports data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs and geospatial indexes with radius queries. Redis has built-in replication, Lua scripting, LRU eviction, transactions and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster.
You can run atomic operations on these types, like appending to a string; incrementing the value in a hash; pushing an element to a list; computing set intersection, union and difference; or getting the member with highest ranking in a sorted set.
In order to achieve its outstanding performance, Redis works with an in-memory dataset. Depending on your use case, you can persist it either by dumping the dataset to disk every once in a while, or by appending each command to a log. Persistence can be optionally disabled, if you just need a feature-rich, networked, in-memory cache.
Redis also supports trivial-to-setup master-slave asynchronous replication, with very fast non-blocking first synchronization, auto-reconnection with partial resynchronization on net split.
Other features include:
Transactions
Pub/Sub
Lua scripting
Keys with a limited time-to-live
LRU eviction of keys
Automatic failover
You can use Redis from most programming languages out there.
Neo4j
source: http://www.tutorialspoint.com/neo4j/neo4j_overview.htm
Neo4j is a world's leading open source Graph Database. It is completely developed by using Java Language by Neo Technology.
Neo4j is -
An open source
Schema-free
No SQL
Graph Database
Graph Database is also known as Graph Database Management System or GDBMS.
Neo4j official website: http://www.neo4j.org
Popular Graph Databases
Neo4j is a popular Graph Database. Other Graph Databases are Oracle NoSQL Database, OrientDB, HypherGraphDB, GraphBase, InfiniteGraph, AllegroGraph.
Graph
A Graph is a set of nodes and the relationships that connect those nodes. Nodes and Relationships contain properties to represent data. Properties are key-value pairs to represent data.
Graph Database
Graph Database is a database which stores data in the form of graph structures. It stores our application's data in terms of nodes, relationships and properties. Just like RDBMS stores data in the form of "rows,columns" of Tables, GDBMS stores data in the form of "graphs".
Elasticsearch
source: https://www.elastic.co/products/elasticsearch
Elasticsearch 6.5 (In the process of updating to the version 7.X ) includes all of the latest advances in speed, security, scalability, and hardware efficiency. It introduces new debugging capabilities to allow developers and administrators to diagnose queries, an all-new geospatial index with supercharged performance.
Real-Time Data
How long can you wait for insights on your fast-moving data? With Elasticsearch, all data is immediately made available for search and analytics.
Real-Time Advanced Analytics
Combining the speed of search with the power of analytics changes your relationship with your data. Interactively search, discover, and analyze to gain insights that improve your products or streamline your business.
Massively Distributed
Elasticsearch allows you to start small and scale horizontally as you grow. Simply add more nodes, and let the cluster automatically take advantage of the extra hardware. Petabytes of data? Thousands of nodes? No problem.
High Availability
Elasticsearch clusters are resilient — they will detect new or failed nodes, and reorganize and rebalance data automatically, to ensure that your data is safe and accessible.
Multitenancy
A cluster may contain multiple indices that can be queried independently or as a group. Index aliases allow filtered views of an index, and may be updated transparently to your application.
Full-Text Search
Elasticsearch builds distributed capabilities on top of Apache Lucene to provide the most powerful full- text search capabilities available. Powerful, developer-friendly query API supports multilingual search, geolocation, contextual did-you-mean suggestions, autocomplete, and result snippets.
Document-Oriented
Store complex real world entities in Elasticsearch as structured JSON documents. All fields are indexed by default, and all the indices can be used in a single query, to easily return complex results at breathtaking speed.
Schema-Free
Elasticsearch allows you to get started fast. Simply index a JSON document and it will automatically detect the data structure and types, create an index, and make your data searchable. You also have full control to customize how your data is indexed.
Developer-Friendly, RESTful API
Elasticsearch is API driven. Almost any action can be performed using a simple RESTful API using JSON over HTTP. Client libraries are available for many programming languages.
Per-Operation Persistence
Elasticsearch puts your data safety first. Document changes are recorded in transaction logs on multiple nodes in the cluster to minimize the chance of any data loss.
Apache 2 Open Source License
Elasticsearch can be downloaded, used, and modified free of charge. It is available under the Apache 2 license, one of the most flexible open source licenses available.
Build on top of Apache Lucene™
Apache Lucene is a high performance, full-featured Information Retrieval library, written in Java. Elasticsearch uses Lucene internally to build its state of the art distributed search and analytics capabilities.